
Models Don't Really Hallucinate Anymore

When reading about AI you will inevitably hear the word “hallucination” thrown about. For the majority of users a “hallucination” just means a verifiably false fact that the model asserts. This can be a made up quote, a made up source, entirely made up claims, etc. I imagine basically all readers will have heard this term frequently cited as a reason AI cannot be trusted
My counter-claim is that the majority of hallucinations are basically just user error and the models are, and have been, unequivocally genius.
Now instead of just saying this like I have for awhile, I actually got around to testing it with the release of Gemini 3.
The Experiment.
Today we are going to follow along with an experiment I ran which I will describe now.
HYPOTHESIS: LLM incorrect responses are due to the model not being given proper context for user queries, NOT a fundamental failing of LLM’s.
EXPERIMENT: Ask the three most recent Gemini models (2.5 Pro/Flash and 3 Pro Preview) to provide financial metrics for given tickers with varying context provided.
PARAMETERS: Each model is tested with the same prompt asking it to return the following list of values/calculations:
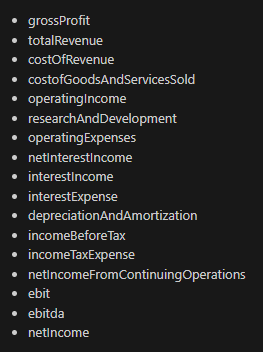
We do so for the tickers NFLX/TSLA/GOOGL/AMZN/META to get some variety in reporting.
The correct answer is determined using a data provider that provides these values using human labor/deterministic software. These values are directly reported in the most recent 10-Q or calculated using values within said 10-Q.
There are four different context types tested:
No Context - Simply provide the prompt and make sure the model has no search tool or coding capabilities.
Google Search Enabled - Enable the model to browse the web for information
SEC filing provided - Enable the model to browse the SEC filing directly
Correct answers provided - Provide the model with the actual values, and then ask it to return them.
Values provided by the LLM within 1% of actuals are counted as correct to avoid non-material errors from rounding.
Simple enough really, we just ask the LLM for some line item metrics that would be included in the typical financial model. So let’s explore.
The Results:
We’ll break these down both by model type as well as context type and include a bit of discussion on where the model struggled and why.
First off, no context (search disabled, no filing provided)
No Context:
Gemini 2.5 Flash - No Context
Gemini 2.5 Flash with no context scored 0/17 on all 5 stocks for a total of 0/85 and 0% accuracy!
Gemini 2.5 Pro - No Context
Gemini 2.5 Pro with no context scored 0/17 on all 5 stocks for a total of 0/85 and 0% accuracy!
Gemini 3 Pro Preview - No Context
Gemini 3 Pro Preview with no context scored 0/17 on all 5 stocks for a total of 0/85 and 0% accuracy!
Summary:
As it turns out, when the model has no capability to index the information you are asking about, it cannot return to you correct information!
This is a very serious consideration whenever asking a model a question where you care about the accuracy of the output! The model *NEEDS* context for anything outside of training data. Training data is going to be information that was in the model providers corpus of training documents 12-24 months ago.
What’s a bit awkward is the majority of users interact with models via the standard web UI’s/apps. Those products attempt to contextually enable search for users, but they cannot spin proprietary documents out of thin air, search is not always enabled when it should be, and users then complain about “hallucinations” because the model cannot arbitrarily pull up to date estimates from Bloomberg.
Our prompt is essentially just “grab these line items from the most recent quarterly financial statements”. The models were returning information from 2023/2024 instead of Q3 2025, so naturally all incorrect.
SEC Filings Provided
Gemini 2.5 Flash - SEC Filings
Gemini 2.5 Flash had a total accuracy of 82% when provided SEC context!
So where did the model struggle?
depreciationAndAmortization: All models and contexts struggled with calculating D&A similarly to the data provider. I imagine this is due to the somewhat arbitrary nature of the metric as reporting isn’t always standardized. It was hard to trace exactly why this was consistently a problem.
ebit: EBIT of course is not typically reported directly and instead the model must understand was EBIT means, and then find the proper lines to calculate. A common mistake was the model mistaking Operating Income, Net Income, and Income before taxes. When those line items were asked for directly the model could figure it out, but the added abstraction of being asked for EBIT led to failure in properly determining where to start. The model did not get a single one of these correct.
ebitda: Naturally if having issues with D&A and EBIT a model will struggle with EBITDA. The Flash model was unable to get a single one of these correct besides NFLX. This is because both EBIT and EBITDA were ~$300m off, but for EBITDA that error was within 1%. For the most part the model was consistent with combining its D&A and EBIT values, it just made errors on one of those two prior to the calculation.
interestExpense: For TSLA the model returned the interest expense with the wrong sign.
operatingExpense: Operating expenses posed some difficulty for the model as it struggles due to definitions. Operating Expense is typically defined as
OpEx = Total Revenue - Operating Income - Cost of Goods Sold (COGS)
The model was instead calculating total operating costs, aka
Total Operating Cost = Cost of Goods Sold (COGS) + Operating Expenses (OpEx)
It was only doing this occassionally, with about a 50/50 failure rate on 2.5 flash and pro
Every single other metric was correct, specifically there were no errors in the more deterministic line items like revenue/gross profit/operating income/net income/etc.
Gemini 2.5 Pro - SEC Filings
Pro did slightly better at 87% accuracy vs the 82% for flash. Areas of struggle were similar:
ebit and d&a and ebitda: the source of almost all errors, again mostly due to starting with the wrong value for E or D&A being off.
NetIncome for TSLA was marginally off for all models using SEC filings, reported as $1.39b instead of $1.37b. The model actually isn’t wrong here, it’s just that the model is using Net Income as reported, and most providers use Net Income Attributable to Common Stockholders!
operatingExpense suffered the same issue in pro as flash with it mixing up Operating Expense and Operating Costs
Every other metric was correct.
Gemini 3 Pro - SEC Filings
Gemini 3 Pro was a bit better here at 89% accuracy, not a dramatic bump from the 2.5 models.
Areas of struggle:
For META cost of revenue was reported with an extra 0, oops! For this experiment the model did have to convert the values from the filing into my strict formatting. Occasionally you see some errors there.
D&A was again a miss here. Gemini 3 however refused to answer when it was unsure while the other models just guessed.
EBIT was actually spot on with 3. EBITDA it refused to answer for a couple tickers as it did not have D&A.
OpEx it improved and only missed NFLX whereas Flash and Pro missed META/NFLX/AMZN
So only 89% headline accuracy but in reality it just missed D&A and NFLX OpEx with a formatting oopsie on META Cost of Revenue. The mistakes were pretty much entirely definitional/formatting and it refused to answer unknown D&A.
Summary:
SEC filings as a source are an infinite % improvement over no context! Surprise! Even 2.5 Flash is very close to perfect outside of D&A with a little bit of help on definitions. Keep in mind this is without any data cleaning, just telling the model to go find random metrics in a 100 page plus document. The average prompt is also completed in 15-30 seconds for Flash and up to a minute or so for 3, which I wager is quite a bit faster than a human.
When testing re-tries (run the prompt 5 times, take the mode) the formatting errors cease. When testing better definitions I was able to get all models to answer everything correctly besides D&A (and thus EBITDA). D&A is just a bit tricky if its only reported on a YTD basis and I’m just feeding the model Q3 reports, so I don’t blame the model.
So with some tuning we can get ~100% accuracy, not bad!
Search Enabled
Search actually sees a pretty interesting distribution of results and is part of why I believe Gemini 3 is a huge unlock!
Gemini 2.5 Flash - SEC Filings
2.5 Flash Accuracy: 33%
For whatever reason the model was able to figure out a large portion of META and GOOGL, then failed everything else. It was able to get revenue for every stock though! For META and GOOGL it was able to get most of the higher level metrics but fell apart on similar areas as with SEC context.
I would not trust 2.5 Flash with search for pretty much anything, which makes sense as it’s not intended to be a reasoning model with sophisticated tool use.
Gemini 2.5 Pro - SEC Filings
2.5 Pro Accuracy: 59%
Pro search was pretty evenly distributed with slight underperformance for AMZN and overperformance for TSLA. META/NFLX/GOOGL were all the same.
Similar error distribution as with the SEC filings but also the occasional random error on things like gross profit or income before tax that even Flash 100%’s with SEC filing context.
Revenue and SG&A were 100% accurate but other lower level metrics just have random fails. Taking the mode of 5 requests will help. Part of the issue with 2.5 Pro is that sources can be total junk and the browse tool that actually pulls context from Google searches also fails occasionally.
On the bright side, 2.5 Pro starts to not return an answer with search if unsure, which it doesn’t do with SEC filings.
Gemini 3 Pro - SEC Filings
3 Pro Accuracy: 86%
Gemini 3 Pro makes it much much less punishing to not provide context, which is super super important!
Most users are bad at providing context. Gemini 3 pro seems to be much better at tool use with dramatically lower errors! D&A and EBITDA are about 50/50 with 3 search. EBIT was perfect.
Interest Expense and Interest Income for META did not return a value, which is promising for recognizing it doesn’t know what’s going on.
Other than that, it had a slight mistake with OpEx by instead calculating total cost of operations for AMZN and was perfect on the other metrics.
If we ignore D&A/EBITDA that’s a 96% accuracy rating with one issue being a definition oopsie! Near perfect
Asking the model later specifically for interest income it was able to one shot it, so likely just a bit of a hiccup and again taking the mode of 3-5 answers is a great way to basically eliminate the small mistakes.
Summary:
Search matters a lot for context with the web UI, which is how the majority of people will interact with AI. Gemini 3 search is now almost at parity with providing raw context (specifically for SEC filings, many other use cases it will fail).
Now the model can still fail to properly enable search, but if we naively assume accuracy goes from 59% to 86% that’s a ~65% reduction in “hallucinations”. Pretty big change for the average user!
Source Context Provided:
Gemini 2.5 Flash - Source Context
Gemini 2.5 Flash with source context scored 17/17 on all 5 stocks for a total of 85/85 and 100% accuracy!
Gemini 2.5 Pro - Source Context
Gemini 2.5 Pro with source context scored 17/17 on all 5 stocks for a total of 85/85 and 100% accuracy!
Gemini 3 Pro - Source Context
Gemini 3 Pro with source context scored 17/17 on all 5 stocks for a total of 85/85 and 100% accuracy!
Summary:
The basic lesson here is that context is a super power and the closer you can get to perfect source context the closer you get to perfect recall! No context, no recall!
It’s imperative to provide full explanations for what you want, full data for what you want to be explored, and retry if something looks off.
Also, never argue with a model! Once it outputs something wrong, just try to identify “why” and adjust your prompt and ask again. Arguing, especially when something is impossible, will just produce hallucinations.
Fin:
If exploring model intricacies is not your idea of a good time and you’d prefer to just research stocks, you can use the tool I’m building with Clarity AI which manages context, prompting, and model settings for you, fine tuning to achieve better results!
It now also comes with fun graphics
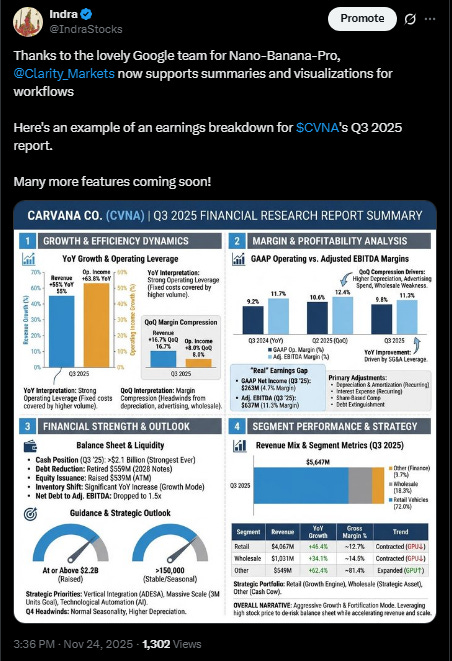
Beyond self promoting, I can’t emphasize enough how much AI usage will shift over the next 6-18 months. It’s clear from these tests that tools like Search provide infinitely better results for some use cases, and search is just the beginning. Model intrinsic capabilities and tool calling capabilities are rapidly scaling, dramatically increasing usability in repeatable enterprise workflows.
The world will look very different by 2027.
Cheers.