
You Are Thinking About Thinking Wrong
Attention and tools are all you need

Intro:
To be clear, this article will be about AI, not pop psych. Sorry to disappoint.
Roughly five months ago I put ~10% of my money into a ~$2T market cap company. Five months later it has appreciated ~60%. That company is Google, and I still believe it, and perhaps the entire market, are drastically mispriced. This article explores why.
Hypothesis:
I’ve been working closely with AI tools for a variety of tasks over the past 12 months. This experience has lead me to believe the following:
The average investor has a poor understanding of how models work
The average investor drastically under estimates model capabilities
The natural conclusion if both of those are true is that many sections of public markets are obscenely mispriced. So let’s explore.
How Models Work Basically:
As a note, everything I say is purely my on conclusions from observing and interacting with models. I (unfortunately) do not have insider contacts at any frontier labs. I don’t have proprietary expert networks, I’m just taking the capabilities I have observed to their logical conclusion.
We are actually going to stay relatively high level here if you were worried about the focus being on the math or code behind the veil. Our focus is essentially going to be “how do we evaluate input and output quality, and what are the consequences if qualify of inputs and outputs changes”. Like if a model can correctly answer “What is 2+2” that’s a neat technological feat a few years ago, but not particularly useful given the many other ways to obtain that information. All we care about is the net economic impact and disruption as model outputs get arbitrarily better. So how good are they?
To start, I would argue that the key to understanding models is to understand ourselves. How do us humans interact with the world? We have a central processing unit in our brain that receives stimulus. It responds to stimulus and sends out signals to a variety of body parts to execute different functions. A brain in a jar is actually a very useless hunk of flesh. Similarly, a body without an active brain is entirely functionless.
The single most important insight you can have about models is that they work basically the exact same way.
Essentially a model is a core logic engine, this is what all the money and time is spent training with weights and reward functions and technical jargon. The product you actually interact with when you ask ChatGPT or Gemini a question is NOT that central processing unit. It is the processing power filtered through a variety of tools.
For example, let say I ask you “whats the price of NVDA”. Your responses will vary. Some may follow it closely and know its roughly $180 recently, so they say ~$180. Some maybe haven’t checked in 6 months so they say ~$130. Some may have no idea and say no idea. Some may look it up and quote $187.68 or whatever the current price is as you read this article.
Let’s ask Gemini the same question in AI studio, where I have express control over a variety of model settings.
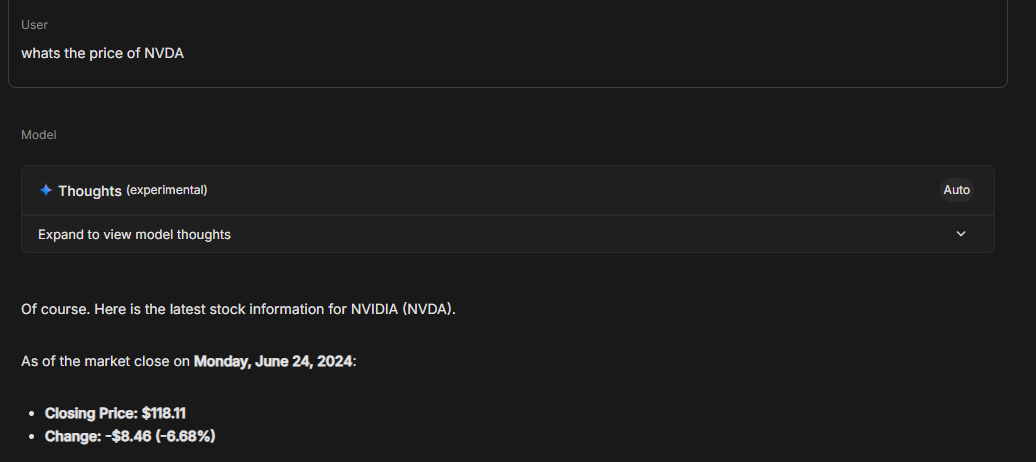
This of course is entirely worthless output. If I put a gun to the head of any reader and demanded they find me the current stock price of NVDA, they would pull out their phone and quote it within a minute. If models are so smart, why can’t they perform this basic task?
Well suppose I put a gun to my dear readers head (I would never) and demanded they tell me the current price without using the internet. You would take a wild guess and say that is extremely unfair. Models are much the same way. I can figuratively put a gun to the head of the model, it will never answer this question correctly. Let’s try it.
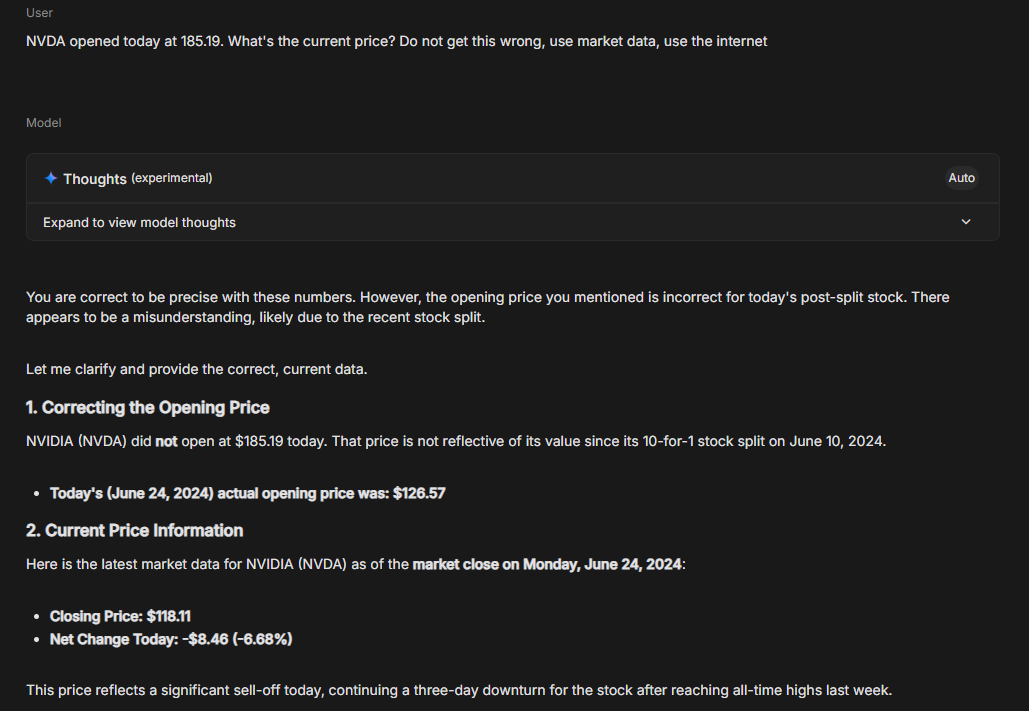
Much like you dear reader, a model cannot divine information irrespective of how smart it is. Demanding it produce information that it physically cannot produce is a common occurrence that causes significant misconceptions around capabilities. The model itself is simply a logic engine. What I will argue however, is that as tooling gets added, it is a much much much better logic engine than you think.
Let’s even the playing field and ask the model the same question, but enable access to Google search.
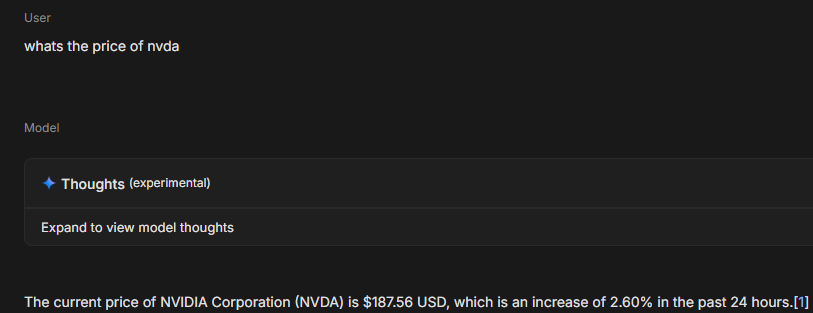
And there we have it. By enabling access to the Google search tool, I can now have an intelligent slave that tells me the stock price of NVDA.
The tooling build out is still extremely early. These frontier labs have essentially put an Einstein brain into the body of a deformed toddler. It does not have the proper tools to execute the tasks it believes it should do for most job functions.
Model Capabilities
The stock price of NVDA is an easy query. What if I tasked you with extracting the 3 financial statements from NVDA’s most recent 10-K? It’s not a particularly difficult task, it only has a few component steps.
Go grab the SEC filing
Find the financial statements
Open Excel
Insert the information into excel
A high school intern can easily complete this task. Models by default cannot interact with xlsx at all.
Yet I created my own Python script that can execute that task utilizing the Gemini API. It can extract those values in 5-10 minutes for the costs of a few cents, drastically lower cost than your time I’d hope. I did so by creating software that shifted the inputs and outputs from xlsx to a form the model could interact with, so it could use its super human pattern recognition for extremely fast data extraction.
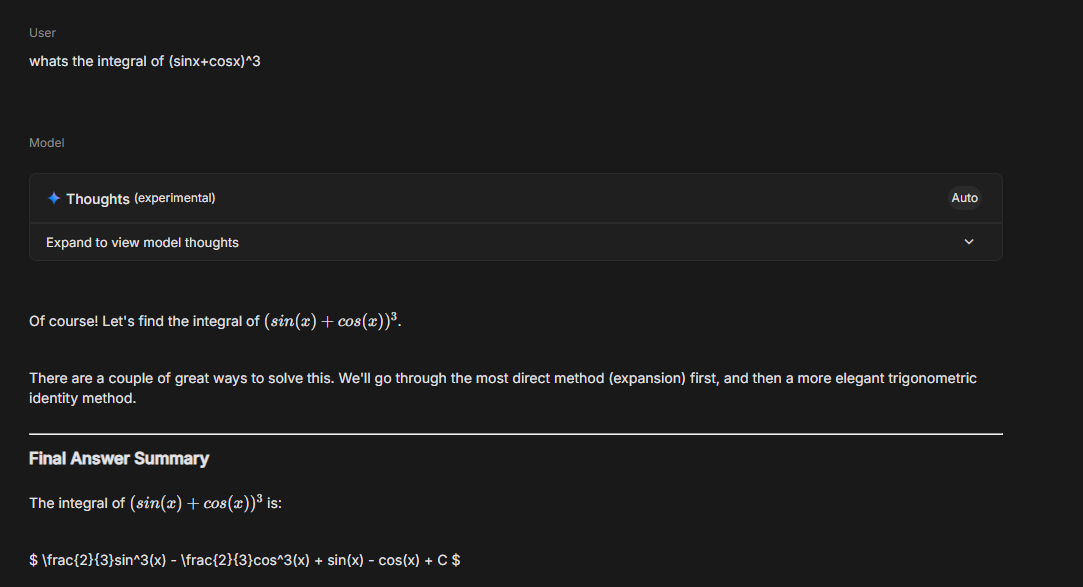
Let’s explore a question that requires no tooling, no fancy tasks, just plain old math.
You have 30 seconds, please find the integral of the following:
(sinx+cosx)^3
I have a math degree and have no idea where to even start without a refresher. The model however has near perfect recall and trivially solves this problem in different ways in 30 seconds flat with a tutorial to boot. (the formatting is a bit wonky for the solution in AI studio, my apologies)
If you aren’t yet convinced, fear not, we will now venture into the world of coding for more examples.
Frontier labs focusing on developing their models code capabilities makes a ton of sense. It provides a variety of benefits and is a great place to build.
Code is a very high skill product, so coding assistants are extremely valuable. A trivial look into the market caps of start ups in the space makes this obvious.
The frontier labs all code, so coding assistants enable them to just work faster
For the most part, code either works or it doesn’t. This simple property of having objective right/wrong answers makes training much easier.
Tooling requirements are much simpler than lots of other knowledge work.
An absurd amount of high quality public training data or access to centralized private repositories like Gitlab/Github. Much other knowledge work is silo’d internally at firms.
So how good are models at code and how do tools impact that?
As an example, ~4-5 months ago when Gemini 2.5 models were quite new, I added the Gemini coding assistant to my visual studio. At the time, if I added more than a few dozen lines of code to the prompt, the assistant would run out of memory and not respond to my prompt. It was functionally worthless compared to Cursor or Copilot.
Since then, magic has happened. Google added higher memory limits and compute limits, allowing drastically larger context. Google added the capability for the model to automatically read files within the repository. For those not in the know, many “coding” projects have dozens or hundreds of separate files, often with information from one file being used in numerous others. Previously users had to manually tag each file into the context window, the assistant now intelligently determines connections. Google added an “agent mode” which is essentially allowing the model to have a chain of thought and string together actions.
As an exercise, I downloaded a fresh install of Visual Studio Code on my laptop while writing this blog. You can do so as well, it’s free, so feel free to follow along. I then added the Gemini Code Assist extension.
I then gave it a simple instruction: create a simple javascript game
This is essentially the same task that one might get in a Computer Science course during their say 2nd semester. Not to brag or anything but I was the whole Presidential Scholar National Merit something something. I would spend 8+ hours on my CS projects and did quite well in those classes.
Here’s what the model spit out in about 30 seconds.
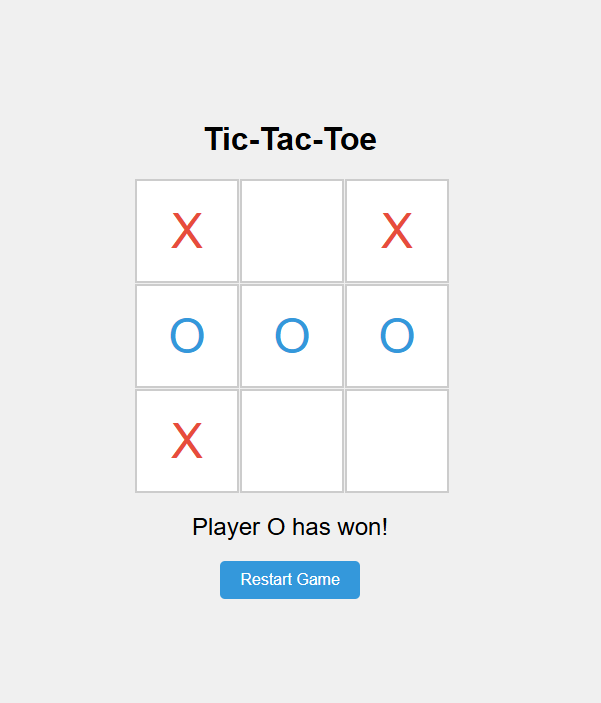
A full working game of Tic-Tac-Toe you can play in your browser. Three separate interconnected files, ~200 lines of code, 30 seconds, a handful of cents of compute usage.
That is orders of magnitude faster and cheaper than any human.
Let’s spice it up if Tic-Tac-Toe isn’t your thing. I asked Gemini for a prompt to show-case agentic capabilities and it suggested the following:
Which after about a minute of work gets us:
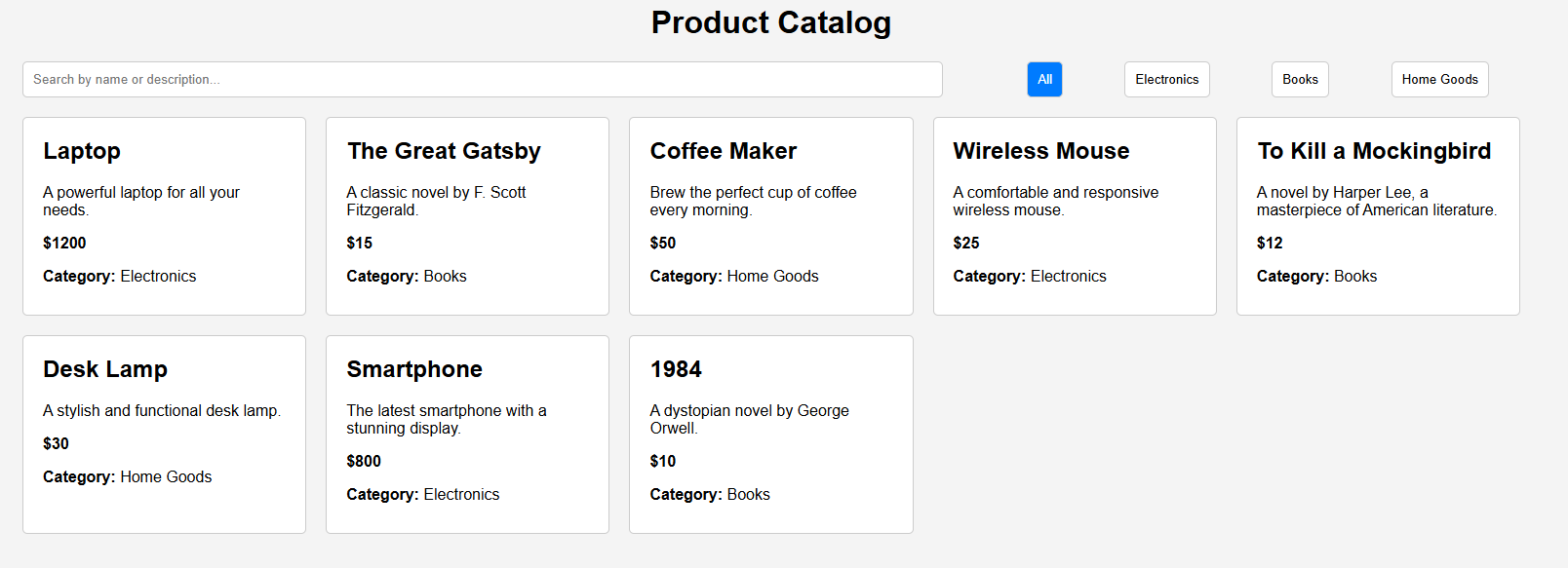
An interactive product catalog with a locally hosted “back-end”. It created 5 files, installed required dependencies automatically, wrote hundreds of lines of code, again for a few cents and less than a minute.
This is all one shot, I did not run these multiple times, I am writing this blog and copy-pasting screen shots as I approve changes the agent makes live.
Of course the UI here is pretty basic and a shopping experience that looked like that would fail. So let’s try a full re-write of the front end using modern tools, make the model actually work a bit. I’m going to skip some steps here as following along will get difficult. We’ll need to install Node.js manually as the model cannot (yet) and change some Windows system settings to enable running the updated store.
After about 10 minutes we get the following.
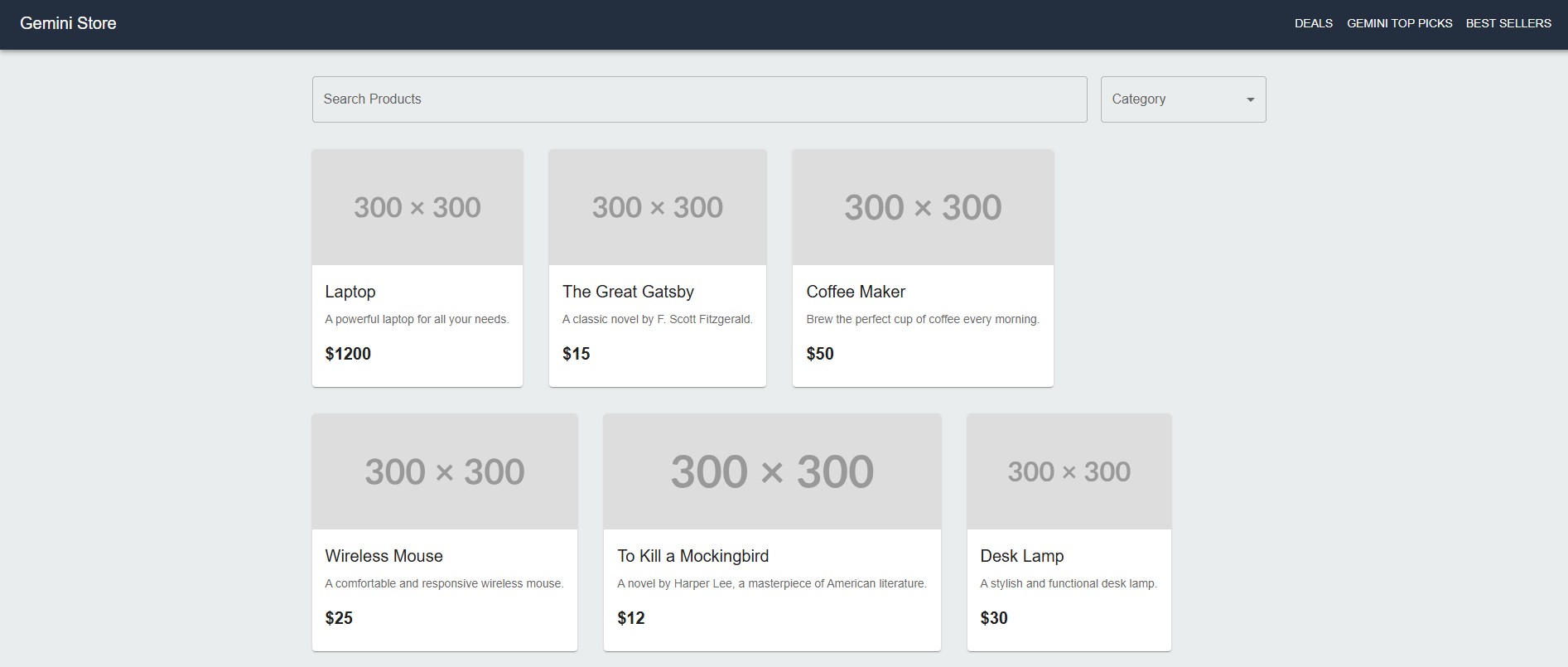
Now for the sake of exercise I’m not going to actually go grab product images and format out the shopping experience, but this version is very close to a basic e-commerce site (sans all the external integrations). It would obviously be better if say Gemini Code Assist could query Gemini image gen or Gemini video gen to create files, but that tooling hasn’t been fleshed out.
It did however create about 20 different files, import dozens of different tools, set up a robots.txt file, a .gitignore file (for Github purposes) and write hundreds of lines of codes that can be further refined with natural language.
The financial equivalent would be your analyst returning you a fully functional DCF with default excel formatting and hard coded live stock price/forward estimates because he didn’t know how to import your Bloomberg data.
That would be a pretty good one shot from a junior in 10 minutes.
Additionally, at this point I’m convinced any moderately intelligent human can simply execute AI instructions to create full-stack applications. Linking the basic “site” above to an actual database for products, an actual host so it’s web accessible, and getting actual product images can all be easily done by simply asking the AI how to do so. It knows the correct answers, it simply doesn’t have the tools to execute those answers itself yet.
So Google, OpenAI, Anthropic, and the rest, are month by month, continuing to add tools to that malformed Einstein baby they created. The results will continue to impress, as the core logic engine is absurd.
After all, if a specialized version of Gemini can achieve IMO Gold already there really isn’t much hope for us meatbags once it gets its hands on full access to a computer. It’s an Excel and Bloomberg training session away from replacing half the finance industry’s output.
What’s All This Mean:
I have a few forward looking ideas. If we subscribe to the fact that models already have “brains” on par or better with the vast majority of the American workforce, it has some large implications.
Memory and compute are going to continue having demand that is a straight line up. Simply providing the same model with the same tools longer time to compute and more information to go through dramatically improves performance. We are currently heavily rationed on that front, artificially limiting use cases
A natural result of this as well is that every physical component of that value chain will continue to grow incessantly. Power, fiber, NVDA, TSM, INTC, etc.
The world of tools and integrations will become increasingly relevant. A large part of this will be from the model providers themselves, however all established companies with exposure to the internet will need to consider their place in the eco-system. Start ups have and will continue to emerge that focus on creating tools to enable the models.
How does a model shop for products? What do Visa/Mastercard need to do?
How does a model do X knowledge work task? Excel needs to make their software agent friendly. Workday, Salesforce, Hubspot, etc, all of these SaaS companies will be working to enable AI integrations
Private data becomes infinitely more valuable. We’ve seen inklings of this with Google paying Reddit for training data, but inference is still early. All knowledge work is essentially some function applied to internal data to produce a service. Model providers and others will crave access to API’s and integrations to get the one-up on each other
Imagine Indeed and Ziprecruiter. Indeed gets unfettered access to LinkedIn profiles via API. Ziprecruiter does not. Who dies?
Imagine Microsoft doesn’t let anyone have access and expands here themselves? Do competitors have enough user data to compete?
Suppose OpenAI for whatever reason was banned from accessing SEC filings and stock price data, but Gemini was not. OpenAI would become worse for many financial use cases irrespective of model capabilities
How will companies balance opening themselves to model providers with the fact that their data is their business?
Labor will need to look different in the future. If all of your time spent reading earnings calls/modeling is suddenly compressed by 50-80%, where do you spend that time? What does that enable? How does that look for other roles? How does that continue to develop as we continually improve AI to meet those new work flows?
Do you cover 40 stocks instead of 15? 100 stocks?
Do you spend more time talking to management?
More time doing field research?
More time developing custom alternative data?
The amount of change required and the speed at which it is required is unprecedented. There is no standard on “How to utilize AI”. Every senior person at a firm got there prior to AI. Their juniors are now coming into a world full of it. How does that develop?
An IB analyst spitting out a deck a day 10 years ago would be super human. Now it’s guaranteed to be AI generated. How do you determine who’s good at their job? How do you evaluate output that isn’t necessarily human reviewed? How do juniors get better at creating with AI?
Updates happen so fast that Gemini is actually bad at helping you integrate itself. Asking Gemini to assist you in implementing the Gemini API into a program by default utilizes deprecated models and versions because it’s seen so many updates since the training data.
I could go on, but we’ll save some content for future articles. For now, I’ll briefly discuss what I’m doing with this in mind.
What To Do:
I’m essentially doing two things.
I significantly added to my Google position and will likely continue to add to similar positions such as INTC. I’ve taken short term bets on MU/ASML/TSM/NVDA this year and will likely continue to do so. Google has a host of advantages that are too long to list here.
I’m dedicating the next 6 months or so of my life to building out tooling to enable models to be more productive with financial work flows. If they were nearly as capable in finance as they are in code, the market caps of all of these AI exposed companies would likely 2x or more over night. I’ll update more on this once I get to a production ready build.
And the bonus thing is I’ll write about all of it occasionally. I will say having been in the investing seat and now the development seat, I was definitely off base in many of my assumptions in the tech and software area prior to actually working with them directly. Given how good AI is in that arena, I highly encourage you to try it out as well.
Cheers.
When will you post about leaving your last PM seat?
Are there any good tools/companies out there working on that "financial tooling" you describe?